


Cluster
Définition :
Un cluster est un emplacement où sont stockés des records. Structurellement proche d'une classe, il permet cependant de gérer le stockage physique de ses données.
Par défaut, un cluster est créé pour chaque nouvelle classe, disposant du même nom. Il est possible par la suite de créer de nouveaux cluster pour cette classe.
A l'insertion d'un record dans la classe, si aucun cluster n'est précisé l'ajout à lieu dans le cluster par défaut de la classe.
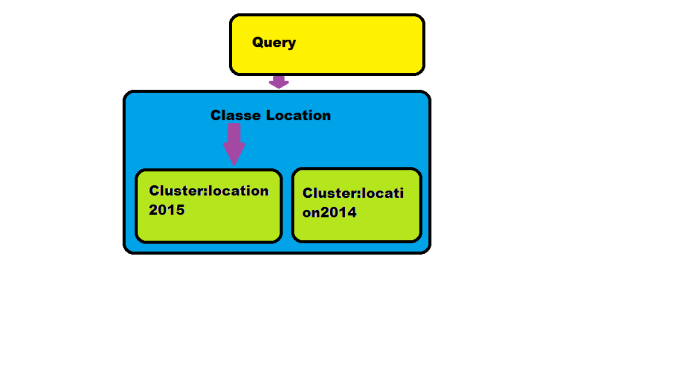
Lors d'une requête sur une classe, de la même façon OrientDB va chercher dans tous les clusters affiliés à cette classe.
Toutefois, il est possible de préciser le cluster sur lequel on veut travailler, que ce soit lors d'une insertion ou d'une sélection.
 | Schéma clusterXclasses |
Remarque : Classe et cluster
Une classe doit nécessairement posséder au moins un cluster. Un nouveau cluster sera crée lors de la création d'un classe.
Remarque :
Il existe des stratégies d'auto répartition des records dans les clusters d'une classe telles que round-robin, ou balanced par exemple
Exemple :
Supposons l'existence d'une classe Location contenant un champ année. Elle contient l'historique des locations des deux dernières années.
Si l'on veut sélectionner les locations de l'année 2014 il convient d'écrire la requête suivante :
SELECT from Location where year = 2014
Maintenant supposons que l'on a créé un cluster pour chaque année de location :
SELECT from CLUSTER:Location2014
En procédant de la sorte on n'a obtenu que les résultats qui nous intéressaient en limitant la recherche au cluster correspondant à l'année désirée.
Il est possible de posséder différents cluster sur différents serveurs physiques. Cela permet :
Optimisation des requêtes (voir exemple ci-dessus)
Parallélisme puisque stockage sur différents disques
Limitation voir suppression de l'usage d'index si le partitionnement en cluster est efficace
Remarque :
Il est possible de créer 32,767 (ou, 215 - 1) clusters dans une base de données




