
Implémentation dans Hadoop
Généralités
Écrit en java à l'origine par Yahoo reprit par Apache.
La gestion des fichiers se fait par l'outil d'Hadoop : HDFS (inspiré du GFS de Google).
Définition : Job
Il s'agit d'une unité de traitement mettant en œuvre un jeu de données en entrée, un programme MapReduce (packagé dans un jar) et des éléments de configuration.
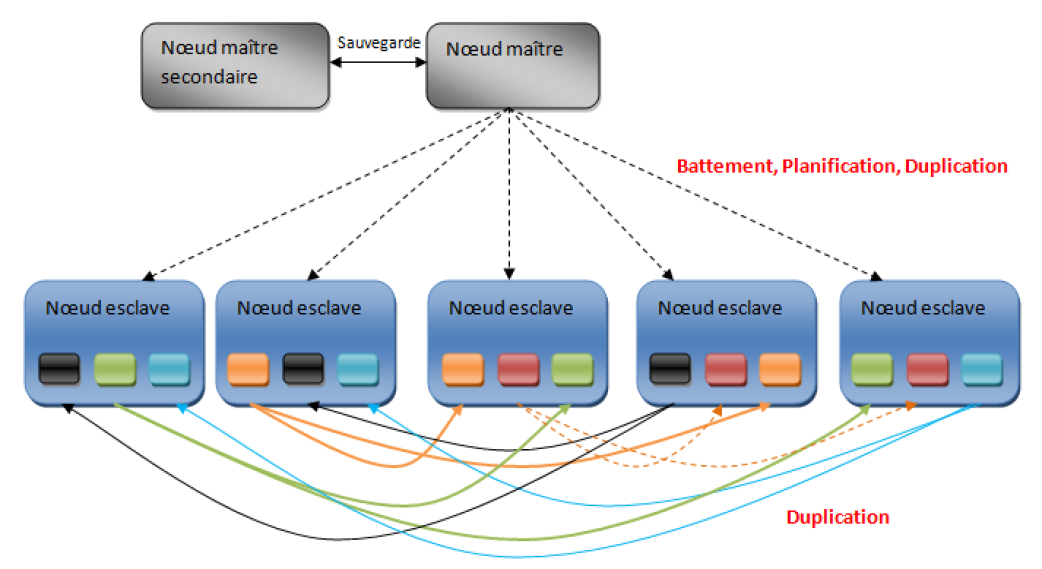
Fondamental : Architecture HDFS
Complément : Les jobs déjà incluent dans Hadoop
aggregatewordcount : Compte les mots des fichiers en entrée.
aggregatewordhist : Traite l'histogramme des mots des fichiers en entrée.
bbp : Utilise la méthode Bailey-Borwein-Plouffe pour calculer les chiffres exacts de PI.
dbcount : Compte le nombre de vue sur une page de BDD.
distbbp : Utilise la formule BBP-type pour calculer les chiffres exacts de PI.
grep : Compte les correspondances avec la reg-ex donné en entrée.
join : Effectue une jointure sur des ensembles de données triés, également répartis.
multifilewc : Compte les mots de plusieurs fichiers
pentomino : Un programme de pose de tuiles pour trouver des solutions aux problèmes pentomino.
pi : Estime PI en utilisant la méthode Monte-Carlo.
randomtextwriter : Écrit 10 Go de données textes aléatoires par nœud.
randomwriter : Écrit 10 Go de données aléatoires par nœud.
secondarysort : Définit un nouveau tri pour le Reduce.
sort : Un programme qui trie les données écrites par randomwriter.
sudoku : Résout des sudoku.
teragen : Génère des données pour le térasort.
terasort : Fait le térasort.
teravalidate : Vérifie les résultats du térasort.
wordcount : Compte les mots des fichiers en entrée.
wordmean : Compte la longueur moyenne des mots des fichiers en entrée.
wordmedian : Calcule la longueur médiane des mots des fichiers en entrée.
wordstandarddeviation : Calcule l'écart type de la longueur des mots des fichiers en entrée.




