Comment ?
Fondamental : Principe Général
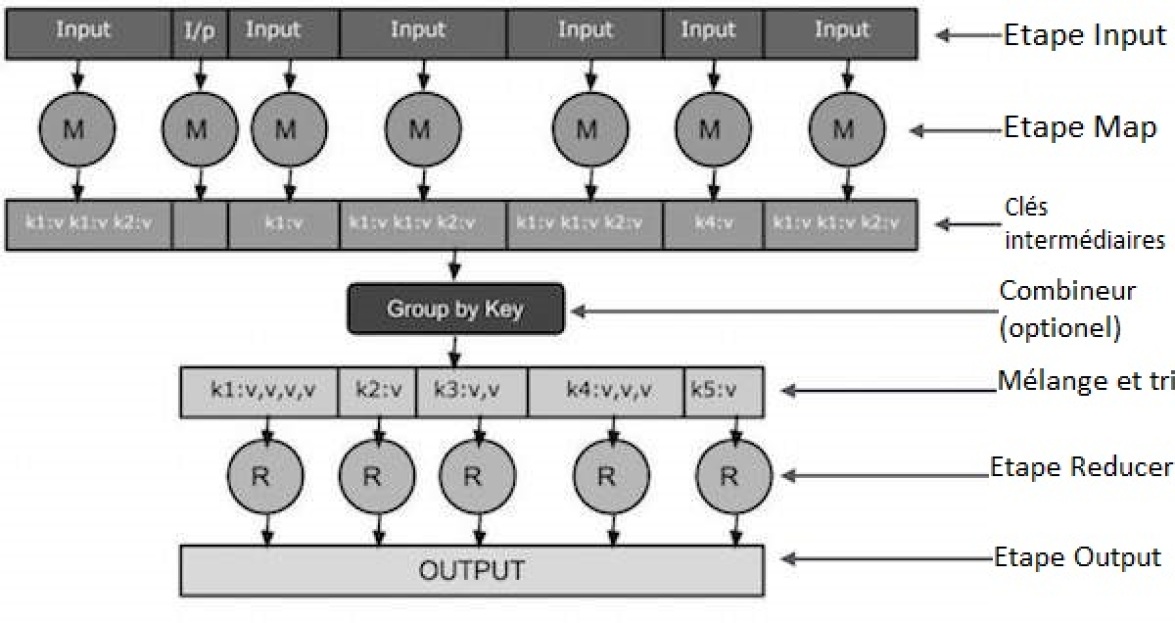
Voyons les différentes phases du MapReduce :
Le fichier est divisé en plusieurs sous fichiers de plus petites tailles. Cela correspond à l'étape Input. Ces input vont être donné au Mapper de l'étape suivante.
Le Mapper prend en entrée des données et va fournir en sortie un autre ensemble de données. Chaque élément (mots) dans les fichiers d'entrée va devenir un tuple <clé, valeur>, que l'on appellera les clés intermédiaires.
Ces clés seront éventuellement combiné à l'aide d'un combiner, mais elles seront surtout mélangées et triées avant de passer à l'étape suivante.
Enfin, l'étape Reduce, celle-ci permet d'associer toutes les valeurs correspondantes à une même clé à une unique paire <clé, valeur>. Cette étape produit les données finales (output).
Complément : Architecture
MapReduce utilise une architecture de type Maître-Esclave où un nœud maître dirige tous les nœuds esclaves.
Une fois qu'un nœud a terminé une tâche, on lui affecte un nouveau bloc de données. Grâce à cela, un nœud rapide fera beaucoup plus de calculs qu'un nœud plus lent.
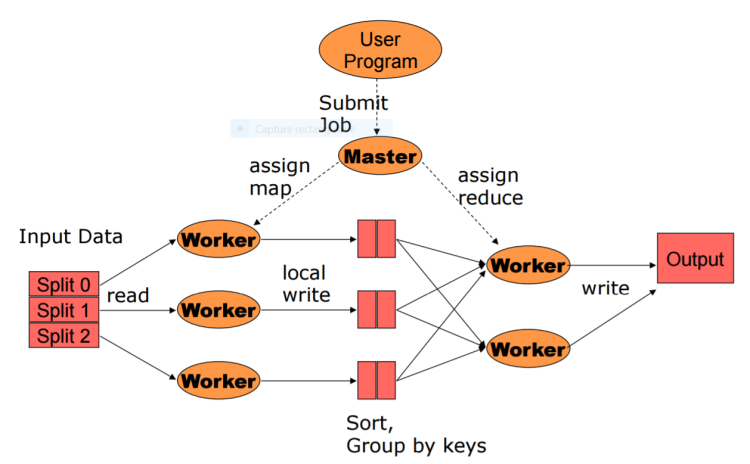
Une tache peut être dans 3 états : inactive, active, terminée.
Les taches inactives sont activées au fur et à mesure que des nœuds de travail deviennent disponibles.
Les taches sont affectées aux workers qui sont les plus proches des données d'entrées.
Quand une tache est terminée, elle envoie au master les adresses et les tailles des données intermédiaires.
Quand toutes les taches Map sont terminées, les taches Reduce commencent.
Tolérance aux fautes
Tolérance aux fautes à grain fin, bien adapté au très grand job.
Les données d'entrée et de sortie sont stockées dans un système de fichiers (distribué et répliqué).
Toutes les données intermédiaires sont écrites sur disque
Si un nœud tombe en panne, sa tache est réaffecté à un autre nœud par le nœud Master.
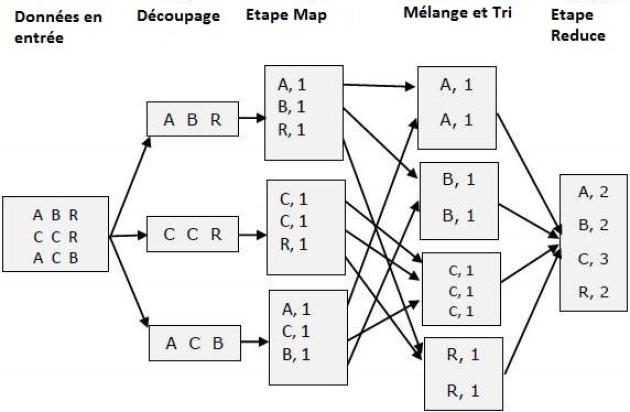
Exemple : Un petit exemple pour mieux comprendre