
Comparatif avec Hadoop/Hive
Redshift y est gagnant ...
plus rapide sur des requêtes d'agrégations (grâce au stockage en colonnes).
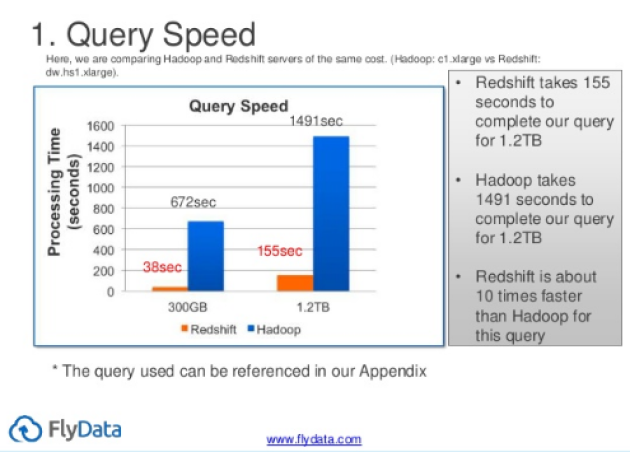
5x à 20x plus rapide en lecture.
Redshift y est perdant ...
plus lent sur des jointures.
scale moins bien Hadoop/Hive si le stockage doit excéder 1.6 pétaoctets.
accepte un type très limité de données, contrairement à Hadoop/Hive.
Ex aequo !
Les prix sont similaires.
Complément : Pour aller plus loin ...
Créer un cluster Redshift : http://docs.aws.amazon.com/redshift/latest/gsg/getting-started.html
Article comparatif Redshift/Hadoop par FlyData : http://www.flydata.com/blog/behind-amazon-redshift-is-10x-faster-and-cheaper-than-hadoop-hive-slides/
Article comparatif Redshift/Hadoop par Xplenty : https://www.xplenty.com/blog/2014/02/hadoop-vs-redshift/
Article comparatif Redshift/Hadoop par AirBnB : http://nerds.airbnb.com/redshift-performance-cost/




