
Redshift : présentation
Définition :
Redshift est un service de Data Warehouse hébergé. Développé par Amazon et basé sur une ancienne version de PostgreSQL, Redshift permet de créer des bases de données optimisées pour les requêtes analytiques.
Fondamental :
Amazon Redshift est une solution OLAP (Online Analytical Processing) proposant un stockage des données en colonne, à opposer aux solutions OLTP (Online Transaction Processing) proposant plus traditionnellement un stockage sous forme de lignes.
Soit une base de données stockant les données suivantes :
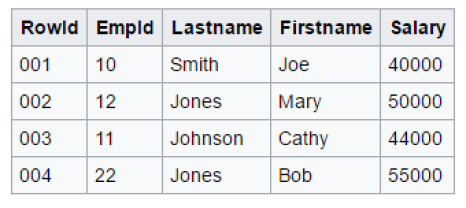
Chaque bloc de données d'une base de données basé sur un stockage en ligne pourra sauvegarder les données de telle manière :

En revanche, les blocs de données d'une solution offrant un stockage sous forme de colonne pourra ressembler à cela :

Une différence subtile mais très importante concerne la manière dont sont mappées les données.
En prenant l'exemple précédent et dans le cas d'un stockage en ligne, RowID est la clef primaire et permet de retrouver les données qui y sont associées.
Dans le cas d'un stockage en ligne, RowID n'est pas la clef primaire. Ce sont les données qui constituent les clefs primaires, auxquelles sont associés les RowID. Ainsi, un bloc de donnée aura la forme suivante :

Où la donnée 'Jones' n'est désormais présente qu'une seule fois.
Une telle manière de stocker les données permet par exemple de retrouver toutes les personnes dont le nom est Jones en une seule opération.
De plus, grâce au stockage en colonne, les requêtes d'agrégation (SUM, AVG, etc.) sont bien plus rapides qu'avec des systèmes ayant une solution de stockage en ligne. Cela s'explique par le fait que l'agrégation entraîne la lecture de moins de beaucoup moins bloc de données, car les informations d'une colonne sont déjà regroupées.
Complément :
Amazon Redshift propose plusieurs services, listés ci-dessous.
Traitement massivement parallèle : les requêtes sont exécutées en parallèle sur plusieurs nœuds. Cela permet d'en accélérer l'exécution.
Compression de données : les données sont compressées par 3, en moyenne.
Sharding : les tables peuvent être en réalité réparties sur plusieurs serveurs.
Automatisation de tâches administratives : il est possible d'automatiser certaines tâches répétitives comme la mise en service et l'arrêt des serveurs.
Une interface intuitive et des options de configuration, surveillance des serveurs faciles à mettre en place.
Un backup de données à tout instant : les données sont régulièrement sauvegardées dans un S3 (Amazon Simple Storage Service), permettant la reprise du service dans les plus brefs délais en cas de désastre. Cela permet d'éviter d'avoir une deuxième installation servant de backup.
Sécurité : les données peuvent être chiffrées, qu'elles soient au repos ou en transit. Il est aussi possible d'isoler certains clusters grâce à Amazon Virtual Private Cloud et ce à tout instant. De plus, les clefs de chiffrement peuvent être gérées avec AWS Key Management System.
Excellent scaling : l'ajout de nœuds peut se faire au besoin et de manière très simple. Redshift propose donc une très grande souplesse quant aux capacité de stockage, pouvant atteindre 1.6 pétaoctets.




