Cas Fantastic : Modélisation avancée du data warehouse
[3h]
Afin d’améliorer les analyses du contexte "Fantastic", on va enrichir le modèle dimensionnel et l'implémenter.
Données supplémentaire
Les données supplémentaires suivantes sont apportés au projet :
fichier
Prices2014.csvdéposé dans un répertoire du serveursme-oracle.sme.utc:/home/nf26/fantastic2fichier
Sales2014déposé dans un répertoire du serveursme-oracle.sme.utc:/home/nf26/fantastic2
Question
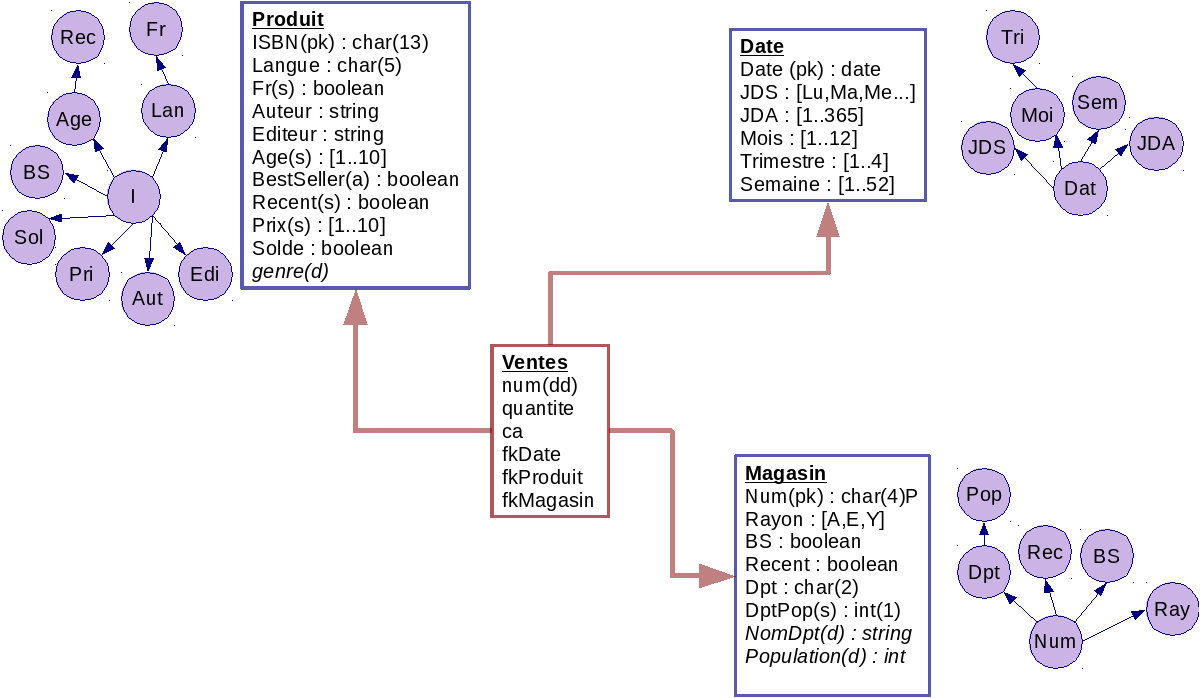
Améliorer le modèle dimensionnel afin d'ajouter :
le numéro de ticket(rappeler pourquoi c'est une dimension dégénérée) ;
le fait quantité (que l'on fixe toujours à 1, ou bien que l'on calcule on regroupant les lignes strictement identiques)
le fait chiffre d'affaire de la vente que l'on récupère du fichier des prix (on fera l'hypothèse que le prix de vente est toujours le prix enregistré dans ce fichier, on pensera à multiplier le prix par la quantité)
les attributs apportés par les nouvelles données
des attributs de documentation (nom du département, genre...)
des attributs de segmentation (population, age de publication...)
un attribut d'agrégation pour savoir si un livre est un best-seller ou non
Solution
Question
Implémenter le modèle dimensionnel et modifier l'ETL en conséquence.
Question
Expérimenter le nouveau modèle avec des questions en rapport avec les modifications apportées.