Les retards à la SNCF 2
Visualisation des données chargées au préalable depuis logstash
Rendez-vous sur la page : http://kibana-api04XX.barbare.ovh
Avant de commencer, il faut configurer l'index qui va être utilisé par la suite
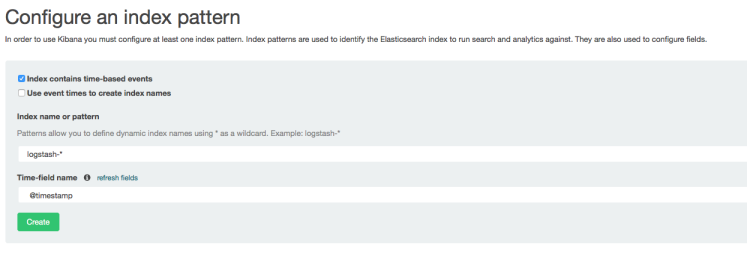
Cliquer sur create
La première chose à faire est d'aller sélectionner la plage de temps et de sélectionner les 5 dernières années
Question
Créer un graphe représentant la régularité des train sur les 5 dernières années
Se rendre de l'onglet visualize et sélectionner un line chart
Sélectionner un nouvelle recherche
Y-Axis correspond à un Unique Count sur le champ régularite
le bucket (group by) est un date histogram
Cliquer sur la flèche verte
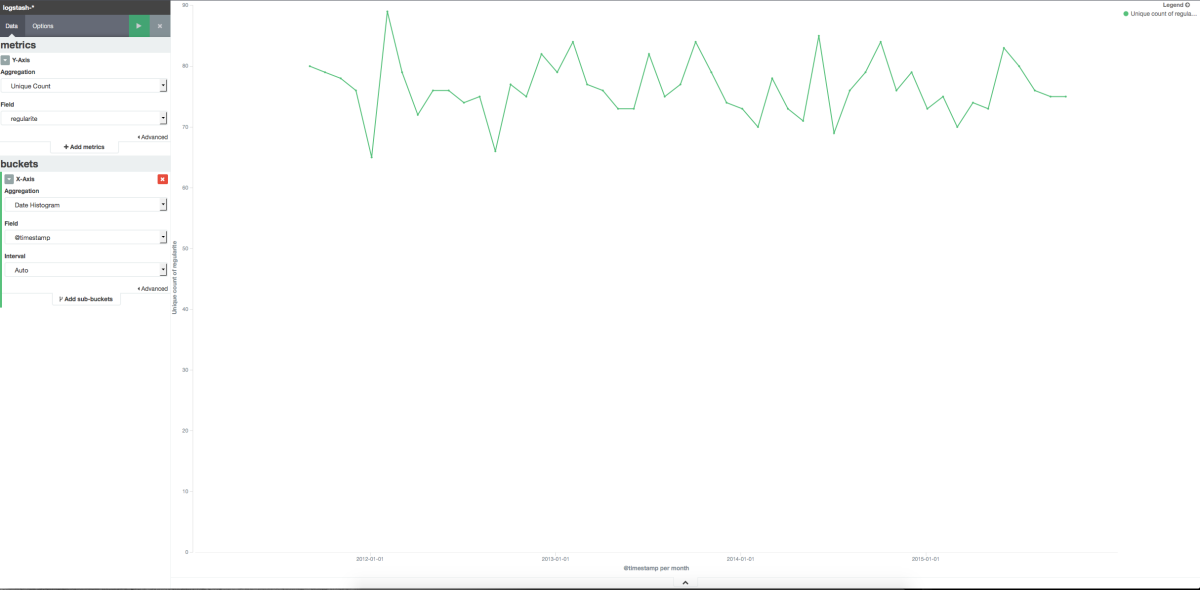
En cliquant sur la petite disquette au bout de la barre de recherche, il est possible de sauvegarde le graphe
Question
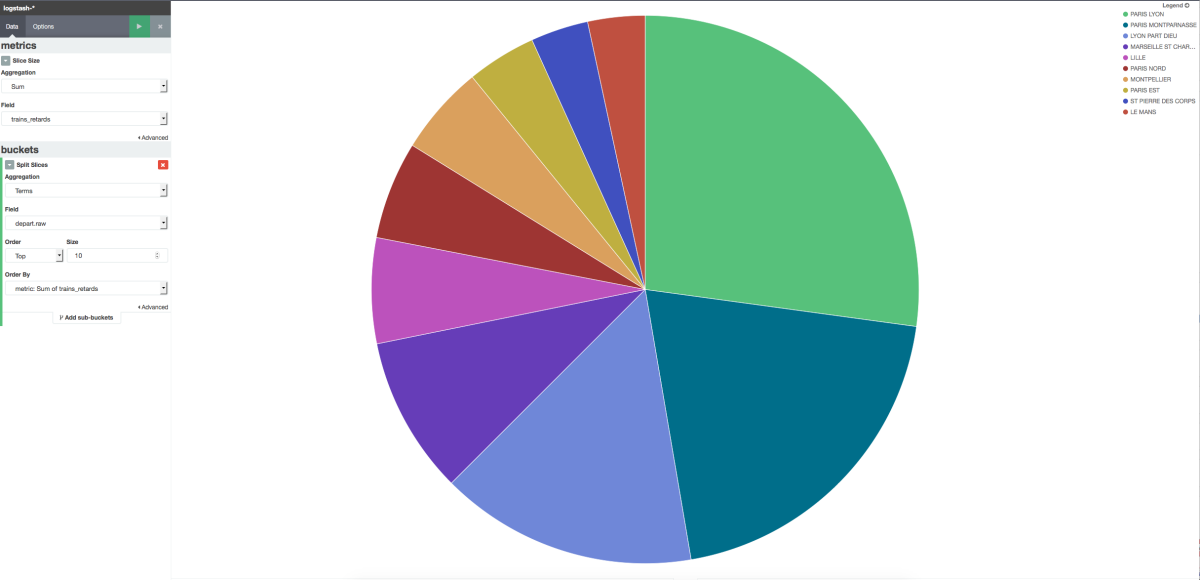
Afficher sous la forme d'un camembert les 10 gares de départ où il y a le plus de retard sur ces 5 dernières années
Se rendre de l'onglet visualize et sélectionner un pie chart
Sélectionner un nouvelle recherche
Slice Size correspond à une somme sur le champ trains_retards
bucket type du type split slices
Question
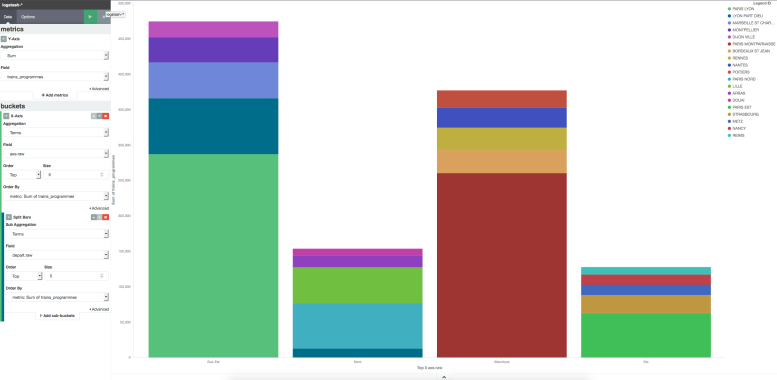
Réaliser le graphe suivant
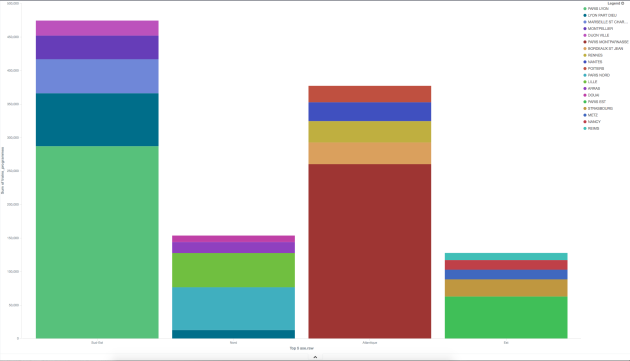
Pour chaque axe, afficher les 5 gares avec le plus de trains programmés
Question
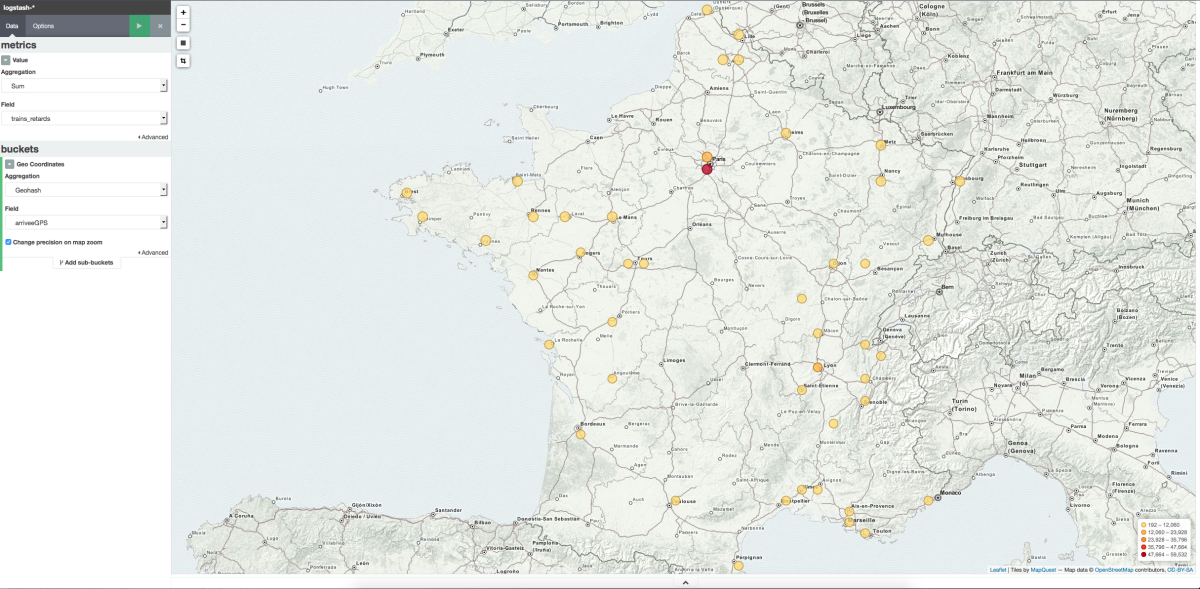
Afficher les gares d'arrivée et le nombre de trains en retard sur une carte de France