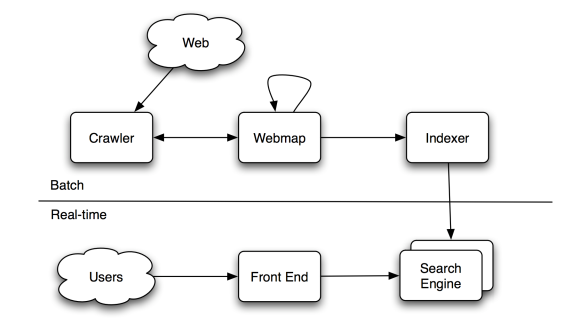
Exemple d'utilisation d'Hadoop
Hadoop chez Yahoo
Janvier 2006 : Naissance d'Hadoop
Mai 2006 : Yahoo deploie 300 machines Hadoop
Octobre 2006 : Le cluster Hadoop Yahoo atteint 600 machines
Avril 2007 : Yahoo possède 2 clusters de 1000 machines
Février 2008 : Yahoo migre son index web dans Hadoop
Février 2008 : L'index de recherche Yahoo est généré par un cluster Hadoop de 10 000 machines
Mars 2009 : Yahoo fait tourner 17 clusters sur 24 000 machines
Mai 2009 : Yahoo est capable de trier 1 Tera de données en 62 secondes avec Hadoop
Juin 2011 : Yahoo possède 42k noeuds Hadoop
Quelques statistiques sur l'index de recherche Yahoo
Graphe du web
100 milliard de noeuds et 1 trillion d'arcs
100 Job MapReduce exécutés périodiquement