
Réplication de données
Fondamental :
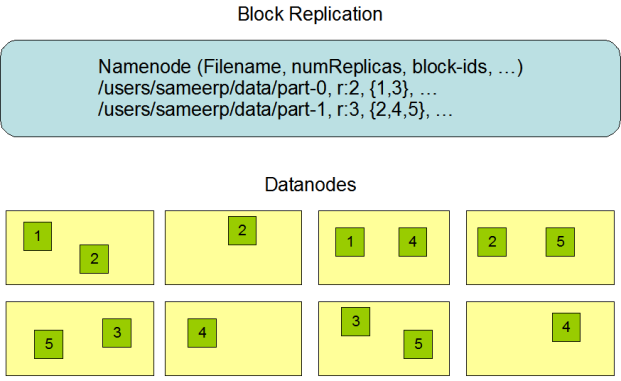
HDFS est conçu de sorte à stocker de fichiers de grande taille dans un cluster. Pour cela, HDFS sépare chaque fichier en une séquence de blocs.
Afin d'éviter la perte de données, les blocs sont répliqués entre les DataNodes dans le cas où un DataNode ne serait pas disponible.
Le facteur de duplication est une option paramétrable dans les fichiers de configuration. Une seule écriture à la fois est autorisé dans HDFS.
Le NameNode reçoit régulièrement des notifications de ses DataNodes :
Un "HeartBeat", pour s'assurer du fonctionnement correct du DataNode.
Un "BlockReport", pour savoir la liste de blocs présents dans le DataNode émetteur.
Source : http://hadoop.apache.org/




