
YARN et l'écosystème Hadoop
YARN
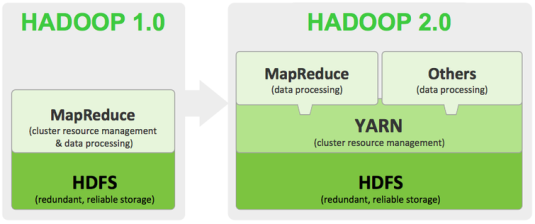
La description de Hadoop comme possédant 2 couches (MapReduce et HDFS) est correcte pour la version 1 de Hadoop. Depuis la version 2, Hadoop a adopté une troisième couche : YARN ("Yet Another Resource Negociator"), un outil de gestion des ressources distribuée.
YARN provient d'un découpage de la première version de Hadoop MapReduce en deux sous-couches :
l'une dédiée à la gestion de la puissance de calcul et de la répartition de la charge entre les machines d'un cluster (YARN)
l'autre dédiée à l'implémentation de l'algorithme MapReduce en utilisant cette première couche
Ce découpage a amené de nombreux autres outils (liés ou indépendants d'Apache Hadoop) à profiter de l’environnement HDFS comme moyen de stocker aisément de grandes quantités de données sans nécessairement MapReduce. Un écosystème d'outils liés à Hadoop a alors émergé et est de nos jours très développé.
Structure de Hadoop 2
Quelques exemples
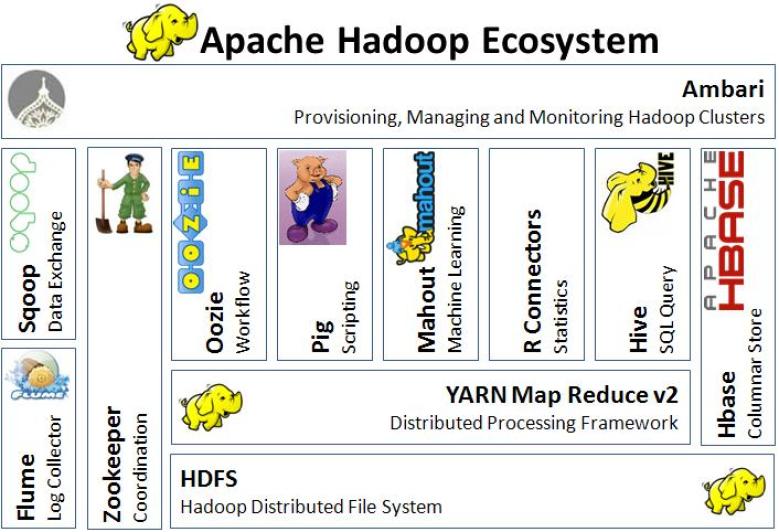
Il existe de nombreux outils basé sur un ou plusieurs composants de Hadoop. Voilà quelques exemples :
HBase, une base de données NoSQL basée sur HDFS ;
Hive, une base de données relationnelle basée sur Hadoop, utilisable en SQL et accessible avec JDBC ;
Mahout, un outil logiciel basé sur Hadoop fournissant un framework et de nombreux algorithmes déjà implémentés pour effectuer du machine learning en se basant sur HDFS et MapReducs ;
Pig, un outil de scripting basé sur Hadoop permettant de manipuler aisément de grandes quantités de données avec un langage proche du Python ou Bash ;
Oozie, une interface Web de gestion des jobs Hadoop pour les lancer et les les planifier aisément en incluant les notions de dépendances de jobs à d'autres jobs ;




