
Lancer Hadoop
Remarque : Pré-requis
Vous devez avoir installé Hadoop pour pouvoir réaliser cette partie et les suivantes. Suivez la documentation d'installation si vous ne l'avez pas déjà fait (première partie de ce cours).
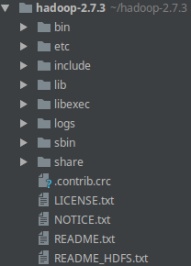
Architecture des dossiers
Avant de commencer à utiliser Hadoop, regardons rapidement l'architecture de dossiers que nous venons de télécharger :
Trois dossiers nous intéressent tout particulièrement ici :
Les autres dossiers sont liés à l'architecture interne d'Hadoop, aux logs ou au librairies partagées. Ils sont nécessaires mais en tant qu'utilisateur, vous ne le modifierez probablement pas. |
Vérifier votre installation Hadoop
Pour interagir avec Hadoop, nous allons utiliser le client : bin/hadoop. Allez dans le dossier Hadoop que vous avez téléchargé et lancez la commande suivante pour vérifier qu'il fonctionne correctement (vous devriez obtenir une aide comme celle-ci) :
$ cd /dossier/vers/votre/hadoop$ ./bin/hadoopUsage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launchYARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get thecredential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
Les deux commandes importantes qui nous intéressent dans ce cours seront :
bin/hadoop fsqui va nous permettre d'interagir avec HDFSbin/hadoop jarqui va nous permettre de lancer des programmes MapReduce
Les modes de fonctionnement Hadoop
Hadoop peut être lancé de trois façons différentes selon l'endroit et le contexte d'exécution :
en mode Standalone, c'est-à-dire dans un seul processus Java
en mode Pseudo-ditribué, c'est-à-dire dans plusieurs processus Java différents mais sur une seule machine
en mode Distribué, c'est-à-dire sur un vrai cluster de machines
Les deux premiers modes sont généralement utilisés pour le développement là où le troisième est dédié à la production.
Lancer Hadoop en mode standalone
Dans le cas du mode Standalone, le client Hadoop créé de lui-même le contexte simulant un serveur en utilisant les ressources du système de fichier local et du processeur de la machine. Cela permet donc de très rapidement tester des fonctionnalités.
Par exemple, pour lister le contenu du dossier actuel, nous pouvons utiliser la commande bin/hadoop fs -ls :
$ cd /dossier/vers/votre/hadoop$ ./bin/hadoop fs -ls
Found 12 items-rw-r--r-- 1 tgalopin tgalopin 84854 2016-08-18 03:49 LICENSE.txt
-rw-r--r-- 1 tgalopin tgalopin 14978 2016-08-18 03:49 NOTICE.txt
-rw-r--r-- 1 tgalopin tgalopin 1366 2016-08-18 03:49 README.txt
-rw-r--r-- 1 tgalopin tgalopin 1366 2017-01-10 23:27 README_HDFS.txt
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 bin
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 etc
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 include
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 lib
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 libexec
drwxrwxr-x - tgalopin tgalopin 4096 2017-01-14 17:53 logs
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 sbin
drwxr-xr-x - tgalopin tgalopin 4096 2016-08-18 03:49 share
Lancer Hadoop en mode pseudo-distribué/distribué
Le mode distribué sera abordé dans la deuxième présentation sur Hadoop, je ne vais donc pas beaucoup en parler ici.




