
Indexation et clés
Indexation
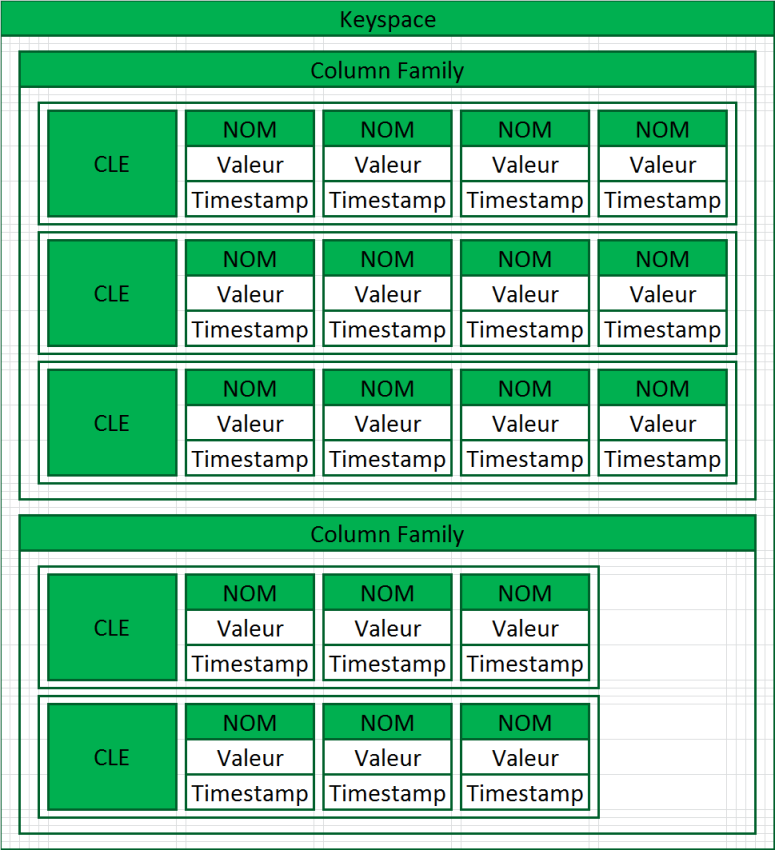
Modèle de données Cassandra :
 Informations[1]
Informations[1]Un index est une structure de données qui permet un accès rapide ainsi qu'une recherche de données par rapport à un ensemble de critères donnés. (http://soat.developpez.com/articles/cassandra/#LVII)
Pour les SGBDR : on utilise les clés primaires, elles permettent de :
accélérer l'accès aux données
garantir l'unicité d'un enregistrement
ordonner les données
Pour les bases NoSQL, un moyen d'accéder rapidement à une donnée est essentiel étant donné le volume de données stockées.
Pour Cassandra, c'est particulier. Une famille de colonnes dispose de 2 index :
un index primaire : c'est l'index des clés de ses lignes.
C'est en analysant cet index nœud par nœud qu'une réponse à une requête concernant les lignes d'une famille de colonne sera trouvée.
un index secondaire : c'est un index portant sur une colonne.
Permet d'appliquer des prédicat d'égalité sur cette colonne (ex : ... WHERE colonne X = y)
Par défaut, le partitionnement des lignes est aléatoire est effectué par le hash MD5, les lignes ne sont donc pas ordonnées.
Le partitionnement peut être ordonné, mais cela n'est pas conseillé car cela demande un travail de distribution des données plus important.
Les clés
Pour Cassandra, la clé de ligne peut être composée d'une ou plusieurs colonnes, la clé est alors composée. Dans le cas d'une clé composée, le premier élément est la clé de partitionnement, les suivant sont les clés de cluster(isation).
Clé de partitionnement
Elle détermine sur quel nœud du cluster la donnée sera stockée.
Clé de cluster(isation)
Elle sert à ordonner les données sur un même nœud. Il est possible d'avoir plusieurs clés de clusterisation pour une même table.
Indexation
La clé de partition est un premier index et est requise.
La clé de clusterisation est un second index optionnel.
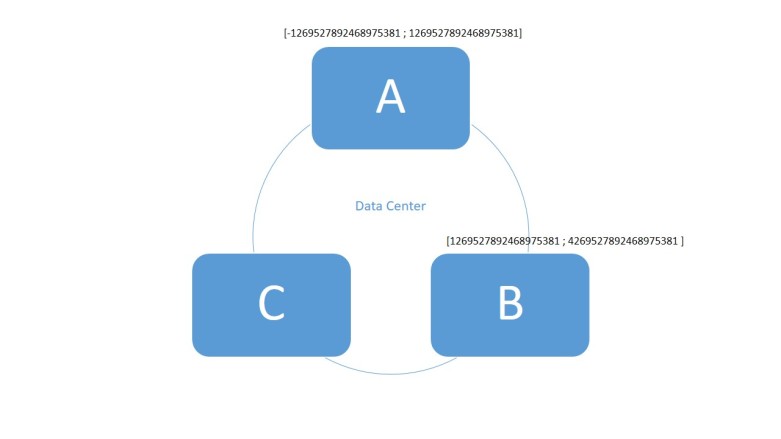
Par exemple : avec ces clés et la répartition des hash ci-contre, la ligne de clé "toto" sera stockée dans le nœud A alors que celle de clé "titi" sera stockée dans le nœud B.
|
Remarque : Ordonnancement
La clé de clusterisation nous permet d'utiliser ORDER BY sur ses données une fois que l'on sait sur quel nœud se situe les données.
Exemple :
Soit la table ayant le schéma suivant :
CREATE TABLE musique (
id uuid,
ordre_musique int, titre text, album text, artiste text,PRIMARY KEY (id, ordre_musique) );
SELECT * FROM musique WHERE id = 62c36092-82a1-3a00-93d1-46196ee77204
ORDER BY ordre_musique DESC LIMIT 50;
Comme expliqué précédemment, on doit d'abord trouver sur quel nœud se situe notre donnée avant de pouvoir ordonner notre résultat. D'où le "WHERE id = ..." qui est indispensable.




